![[Translate to english:]](/fileadmin/_processed_/1/f/csm__c__AdobeStock_your123__270047769_1bf6c5afc0.jpg)
Critical infrastructures that underpin our civilization are becoming increasingly complex. They span domains that were never thought to be integrated in the past and face new threats, from volatile markets and high levels of renewable, distributed energy sources to cyber-attacks. Adversarial Resilience Learning is a new artificial intelligence methodology for the analysis and resilient operation of complex, critical cyber-physical systems.
Cyber-physical systems have undergone an unparalleled transformation in recent decades. This is particularly evident in our energy grids: Driven by the necessary expansion of renewable energies, this digital transformation toward the smart grid confronts not only the higher volatility of energy generation, but also new, more direct market concepts, Internet-of-Things trends, and the seemingly ubiquitous application of artificial intelligence algorithms designed to increase the efficiency of our energy systems. However, this new system can no longer be fully mastered with the analysis and control methods we are familiar with—we are far from understanding the link between digitalization and critical infrastructures.
Instead of viewing artificial intelligence as a potential threat to the stability of our power supply, we turn the tables in Adversarial Resilience Learning (ARL): two agents, attacker and defender, compete for control of a cyber-physical system. They have no explicit knowledge of each other's actions, but by observing the effects, the attacker explores the system and uncovers vulnerabilities, while the defender learns from the attacks to ensure resilient operations. Through mutual learning, ARL agents help designers and decision makers find vulnerabilities in the system and loopholes in market regulations, and operators reliably manage the network even in complex, rapidly changing information environments.
In the process, ARL is developing a new methodology in the field of artificial intelligence: The agents with their non-congruent, possibly even diametrically opposed goals are continually forcing themselves to adapt. Not knowing whether an effect is part of the environment or the action of another agent leads to System of Systems Reinforcement Learning. ARL agents thus learn more robustly and efficiently than classical reinforcement learning agents could.
The ARL concept spans both methodological research in artificial intelligence and applied research in the analysis and secure operation of complex cyber-phylic systems.
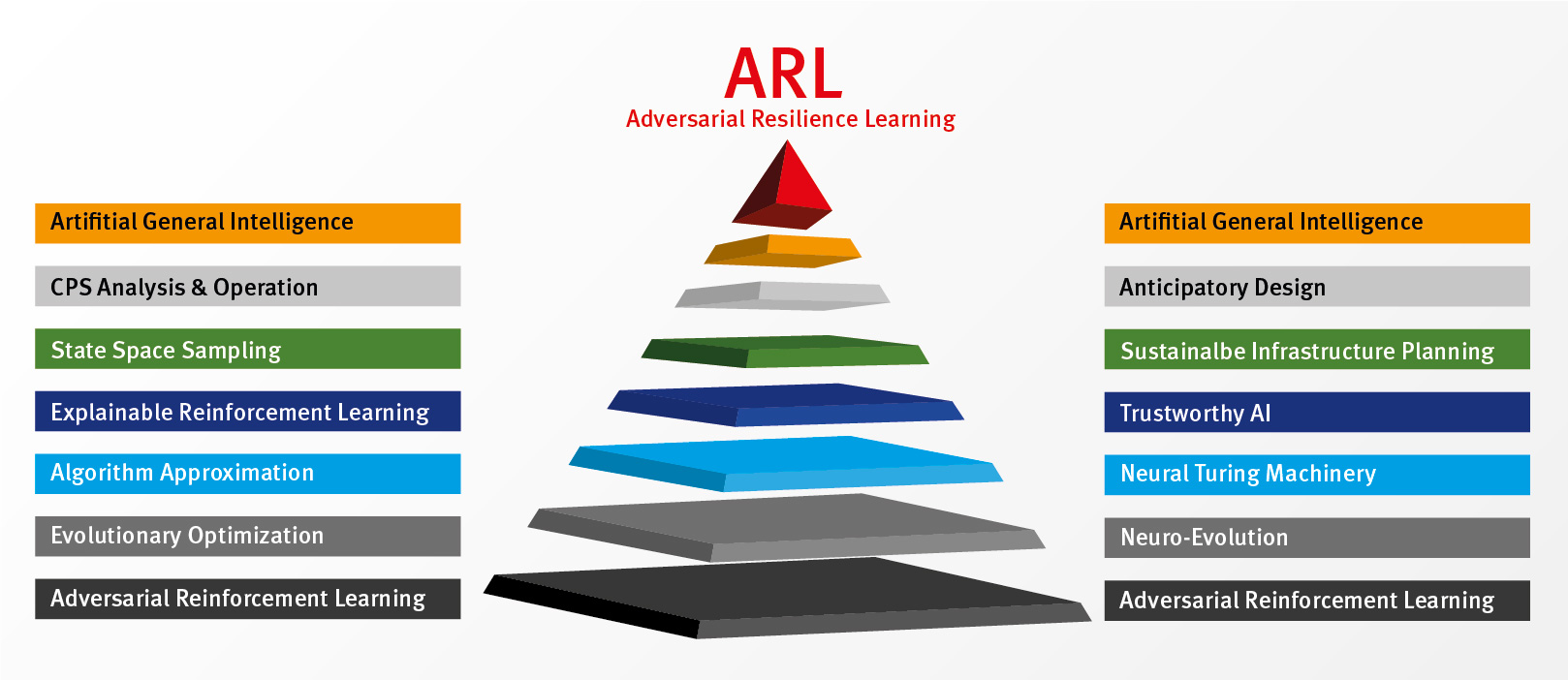
Adversarial Reinforcement Learning
Modern approaches in reinforcement learning have shown that self-play - the play of different instances of an agent against each other - can be effectively used to master even complex environments like the game Go. ARL extends the concept by assigning sensors and actuators to agents that do not carry any domain knowledge, but simply have the definition of a mathematical space to describe valid values. Also, ARL agents know nothing about each other, allowing counterparts to develop effective strategies to achieve their goal in a highly variable, partially perceptual environment.
In addition, the ARL concept and the ARL reference implementation allow different reinforcement learning algorithms to compete against each other, e.g., to evaluate the effect of A3C against A2C or DDQN. The ARL reference implementation thus also becomes a benchmark system for intelligent operation management of critical infrastructures.
Evolutionary Optimization
Evolutionary algorithms are becoming a serious alternative to classical gradient descent methods and show strengths especially in the area of reinforcement learning. In particular, ARL benefits with its scope of evolutionary algorithms, which have fewer problems with non-convex optimization problems and allow the combination with neuroevolutionary algorithms.
Neuroevolution
Usually, in Deep Learning applications—and Deep Reinforcement Learning is one of them—, the shape of the artificial neural network is predetermined by the developer. But the concept of ARL methodology expects full adaptivity: Since systems are to be explored and controlled that are partially unknown even to the experimenter, the latter cannot be given a default about the information capacity of the artificial neural network at the heart of the agents. Neuroevolution approaches, where the architecture and parameters of the network are evolved by the algorithm, have already been shown to be equal and sometimes even superior in standard benchmarks.
Neural Turing Machinery & Algorithm Approximation
The goal of the ARL methodology is to enable agents to be capable of meaningful actions beyond concrete models. This is not intended to involve new training or transfer learning: ARL seeks to develop methods for approximating algorithms. One such way is to transfer the Neural Turing Machines concept to the domain of complex CPS. The Differentiable Neural Computer, a representative of Neural Turing Machines, has already proven its potential.
Explainable Reinforcement Learning
Any application of artificial intelligence, provided it is used in critical infrastructures and CPS on whose well-being human lives depend, must meet high standards. Conversely, this means that the actions of an agent become comprehensible and thus verifiable to some extent. In the field of reinforcement learning, which comes closest to the idea of fully adaptive ARL agents, a large research gap exists here so far.
State Space Sampling
Surrogate models are used when the use of true simulation models is time or otherwise resource intensive. They represent approximations of the original model that are lightweight, yet accurate enough for the intended use. To generate them, the original model must first be analyzed: sampled. This sampling must build up as efficiently as possible a large information content for the surrogate model. Efficient sampling, especially in the “fringe regions” of the model state space, is automatically performed by training the ARL agents.
Sustainable Infrastructure Planning
ARL ist nicht nur ein Treiber methodischer Forschung in der künstlichen Intelligenz, sondern auch findet seine Anwendung in Analyse, Betrieb und Aufbau von Infrastrukturen. So lässt sich mit ARL die Erweiterung von Energienetzen strategisch planen: Ein evolutionärer Algorithmus kann Netzausbauszenarien und die Einbringung eines wesentlich höheren Anteils von erneuerbaren Energien vorschlagen, während die ARL-Agenten als komplexe Fitnessfunktion das neue Szenario bewerten.
CPS Analysis & Operation
In its application, ARL shows its strengths especially in the exploration, analysis and operation of complex cyber-physical systems. The PYRATE research project, for example, is developing an intelligent, learning system for analyzing CPS. It uses a system of software agents that adapts fully automatically to the CPS based only on a description of the existing sensors and actuators, which is represented in the study by a so-called digital twin. The PYRATE software technology independently develops a model of the system; this ability to adapt on the basis of the interfaces also gives rise to the name of the polymorphic agents. These agents coordinate to find a weak point where the subdomains of the overall system work within nominal parameters, but the overall system is destabilized in the interaction of the domains by emergent effects.
In particular, so-called attackers, i.e., market players who exploit “loopholes” in regulations, are the target of the analysis strategy. PYRATE enables experts to close these loopholes, which would not have been noticed in a traditional view of a CPS. The attackers are also countered by AI defenders who are tasked with keeping the system operationally secure. They learn their strategy for maintaining operational security directly from the attackers.
Anticipatory Design
The ARL agents training in competition with each other are able to support a human in dealing with complex situations. Instead of operating the CPS itself, the agent supports the cognitive performance of a human in a control room as a defender, so to speak. Particularly in modern power systems, operators are literally flooded by a plethora of system messages even during minor incidents. To master the situation, aggregate and weight information, ARL agents train against each other. In the end, they can even reconfigure the user interface dynamically, according to both the situation and the user's preferences, to achieve the optimal situation representation and support human judgment.
Artificial General Intelligence
More broadly, ARL hopes to be a building block in the evolution toward general artificial intelligence. The training methodology can be a contributor to better generalization in reinforcement learning-like scenarios, while the neuroevolutionary adaptivity of the agents allows learning “from scratch.” The extension of algorithm approximation may ultimately enable abstraction: Artificial General Intelligence is a lofty, yet unattainable goal, but along the way ARL may be a veritable building block.


![]()